网络爬取与网络抓取:有什么区别?

Jason Grad
Proxy Network Manager


许多人常将 网络爬取(web crawling)与 网络抓取(web scraping)混为一谈,但实际上它们是两种不同的技术。
快速摘要:网络抓取 是从网页中提取特定信息(如价格或产品详情);而 网络爬取 更像是派出一个机器人探索互联网,收集所有能找到的页面,通常用于搜索引擎。虽然它们听起来相似,但各自有不同的用途,选择使用哪种技术取决于您的需求。
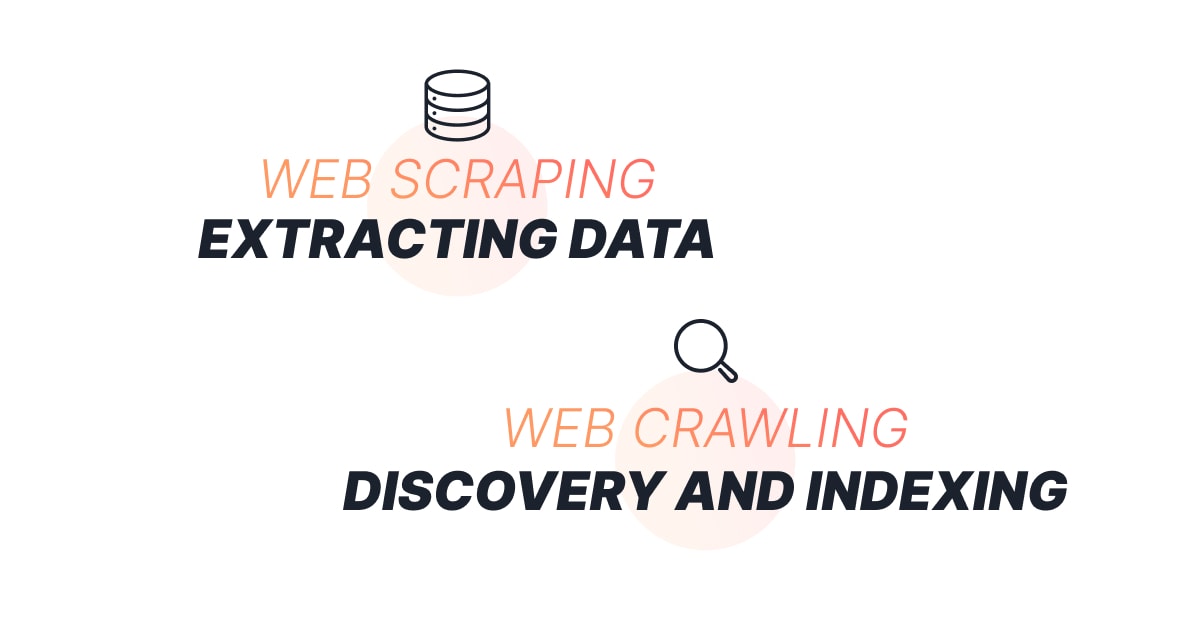
本文将解释网络爬取与网络抓取之间的区别,并通过示例说明各自的应用场景及它们如何结合使用。
网络抓取是一种用于从网站中提取特定数据的技术或过程。可以将其看作从网页中挑选和选择所需信息的方式,比如产品价格、评论或联系信息。网络抓取工具可以自动化从多个网站复制这些数据的过程,从而节省手动收集的时间。
例如,如果您经营一家追踪竞争对手价格的公司,您可以设置一个抓取器,自动检查并提取竞争对手网站上的信息。网络抓取还广泛用于潜在客户挖掘、市场调研或趋势监测。
网络抓取通常包括以下三个步骤:
网络抓取已成为企业增长的重要工具。以下是常见的应用场景:
网络爬取是系统化地浏览互联网以发现并收集网页的过程。爬虫(也称为“机器人”或“蜘蛛”)常被搜索引擎用来索引网络内容。爬虫扫描每个页面,跟随链接访问更多页面,构建互联网的全面索引。
常见示例是 Google 的网络爬虫(Googlebot),用于发现新页面并将其添加到搜索索引中。
以下是两者的主要区别:
<table class="GeneratedTable">
...
网络爬取与网络抓取在许多场景中是互补的。爬取用于发现页面,而抓取用于提取特定数据。在执行这两种任务时,住宅代理的使用有助于实现匿名性并绕过反爬措施。

